habr (@habr@zhub.link)
Интеграция TOTP в OСSERV (FreeRADIUS + FreeIPA)
В данном руководстве приведена инструкция по внедрению двухфакторной аутентификации (2FA/TOTP) для VPN-доступа на базе OCSERV (OpenConnect Server) в связке с FreeRADIUS и FreeIPA.
https://habr.com/ru/articles/1027944/
#ocserv #freeradius #freeipa #docker #OpenConnect
Show Original Post
habr (@habr@zhub.link)
Auto AI Router: высокопроизводительный прокси-роутер для LLM API на Go
Auto AI Router — лёгкий прокси-роутер на Go, который принимает запросы в формате OpenAI API и прозрачно распределяет их между несколькими провайдерами и ключами с балансировкой нагрузки, защитой от банов и контролем RPM-лимитов. Читать далее (многобукав)
https://habr.com/ru/articles/1027878/
#go #github #llm #openai #vertex #gemini #litellm #docker #dockercompose #router
Show Original Post
r (@r@bsky.brid.gy)
docker compose in production — on 4grab.com health checks, zero-downtime deploys, secrets management, multi-service setups. beyond the tutorial. https://4grab.com/pay.php?id=ptag_69c43b9ddbd65 #prompt #docker #devops #containers
Show Original Post
simonespinedi (@simonespinedi@mastodon.social)
Sometimes Cisco IOL doesn't perform bootup correctly when used as a container. During my test case, devices were falling into a startup dialog config, preempting SSH to be applied properly.
I made a simple demonstration on how to fix Cisco IOL "startup dialog" when building a containerlab topology.
#Containerlab #Cisco #NetworkEngineer #Docker #CiscoIOL
https://youtu.be/5xZYi8W9Wmg?si=O8t-oLTzyrKJN5iO
Show Original Post
post (@post@sh.itjust.works)
Trivy, KICS, and the shape of supply chain attacks so far in 2026
https://sh.itjust.works/post/59106565
Show Original Post
marvinvonpapen (@marvinvonpapen@social.tchncs.de)
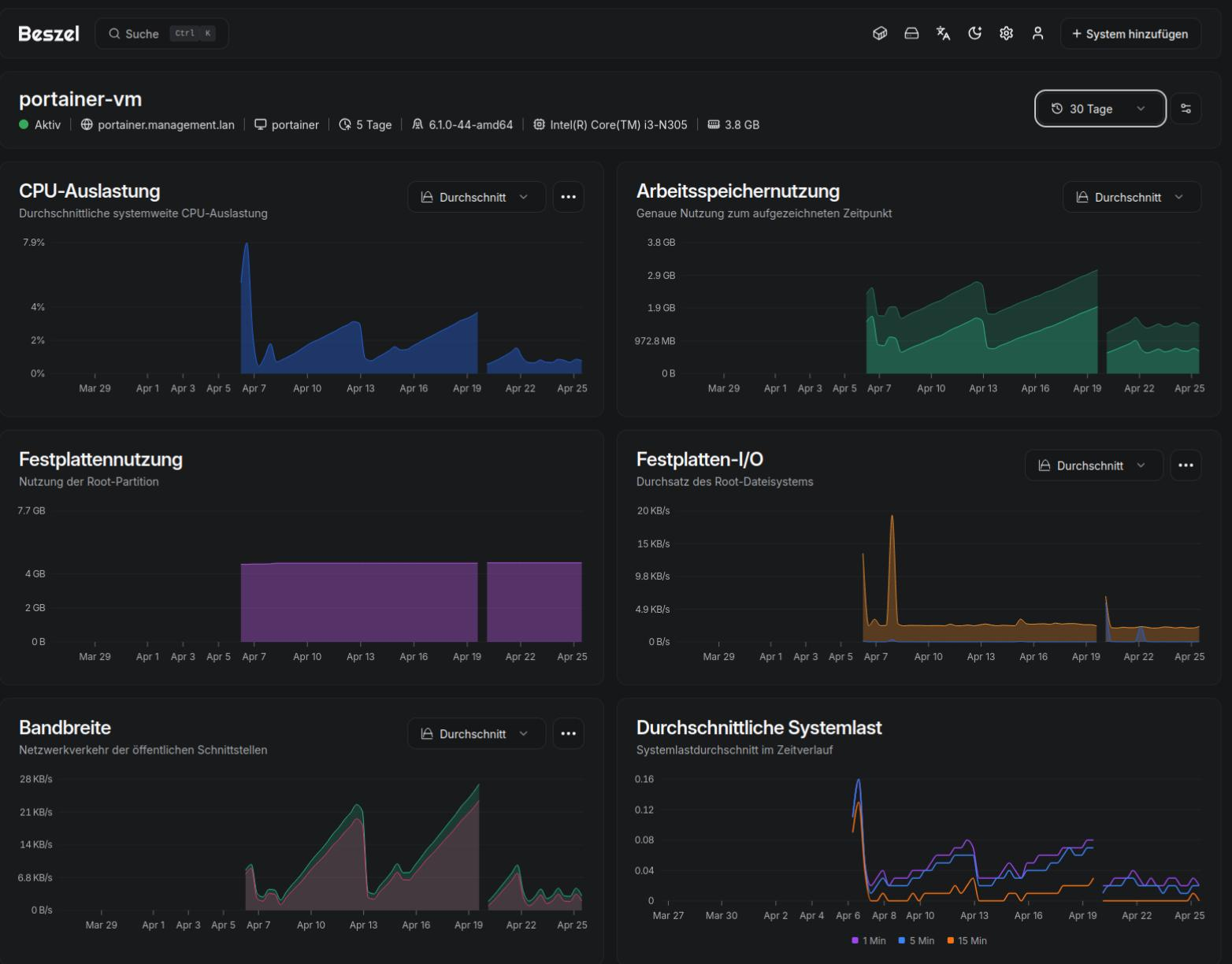
Beim Einsatz von Docker rootless mit Portainer und Anbindung von mehreren Docker-Umgebungen via API, die alle 5 Minuten abgefragt werden: RAM, CPU-Last und Bandbreite steigen stetig. Nach wochenlanger Recherche nun vermutlich die Ursache gefunden und ein Workaround in Nutzung.
Ursache: Es werden UNIX-STREAM sockets geöffnet und nicht wieder geschlossen.
Maßnahmen:
1) slirp4netns gegen pasta ausgetauscht (Schwächung der Symptome, keine Lösung)
2) DNS via deamon.json mitgeteilt (Nebenthema)
3) Docker-Neustart 1x am Tag 😖
Details gibt es hier: https://github.com/docker/docker-py/issues/3251#issuecomment-4276522526
Hat jemand ähnliche Erfahrungen gemacht?
#selfhosting #homelab #docker #workaround
Show Original Post
RockyC (@RockyC@fosstodon.org)
@Cali I had a misunderstanding of LXC vs Docker and thought I needed to run the equivalent LXC in Proxmox instead. The containers I run probably should remain in Docker for easier management and lower overhead.
So the new plan is to put Docker in a VM and run my containers there. Proxmox adds a layer of flexibility that I’m still learning to understand.
#Linux #HomeLab #SelfHost #Proxmox #Docker
Show Original Post
lopeztel (@lopeztel@fosstodon.org)
#simplecss experiment, testing on httpd
#docker container.
AI assisted workflow with some baby sitting but, in my defense I'm not a web developer and just wanted something that works...
Show Original Post
Arint (@Arint@arint.info)
RT @GBminA: Built Qwen/Qwen3.6-27B-FP8 on vLLM with a non-default stack. - Custom image: http://ghcr.io/aeon-7/vllm-spark-omni-q36:v1.2 - Base model: Qwen/Qwen3.6-27B-FP8 - Draft model: z-lab/Qwen3.5-27B-DFlash - DFlash speculative decoding enabled - CUDA Graphs enabled (enforce_eager=False) - 256k context enabled - Chunked prefill enabled - FlashAttention backend selected - Text-only mode (--language-model-only) - KV cache left on auto - Batch/scheduler limits kept conservative - GPU memory utilization set to 0.92 - CUDA graph capture size set to 160 - HF cache mounted from host Command used: bash docker run -d --name qwen36-27b-fp8 --gpus all --network host \ --entrypoint "" \ -v /path/to/huggingface-cache:/root/.cache/huggingface \ -e HF_HOME=/root/.cache/huggingface \ -e TORCH_MATMUL_PRECISION=high \ -e PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True \ -e NVIDIA_FORWARD_COMPAT=1 \ -e VLLM_MEMORY_PROFILER_ESTIMATE_CUDAGRAPHS=1 \ http://ghcr.io/aeon-7/vllm-spark-omni-q36:v1.2 \ python3 -m vllm.entrypoints.openai.api_server \ --model Qwen/Qwen3.6-27B-FP8 \ --speculative-config '{"method":"dflash","model":"z-lab/Qwen3.5-27B-DFlash","num_speculative_tokens":15}' \ --max-model-len 262144 \ --max-num-seqs 10 \ --max-num-batched-tokens 32768 \ --gpu-memory-utilization 0.92 \ --attention-backend flash_attn \ --enable-chunked-prefill \ --language-model-only \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder \ --default-chat-template-kwargs '{"preserve_thinking": true}' \ --override-generation-config '{"tem…
mehr auf Arint.info
#bash #docker #huggingface #openai #Qwen #qwen3 #Qwen3527 #Qwen3627 #qwen3627 #vLLM #vllm #arint_info
https://x.com/GBminA/status/2047243225631498341#m
Show Original Post
GripNews (@GripNews@mastodon.social)
🌘 Lightwhale 3:讓 Linux 伺服器重拾樂趣!
➤ 告別維護噩夢,擁抱隨插即用的容器化體驗
✤ https://lightwhale.asklandd.dk/
Lightwhale 3 是一款專為執行 Docker 容器而設計的極簡主義作業系統。它捨棄了繁瑣的安裝與維護流程,透過「唯讀映像檔」的不可變核心架構,確保系統的穩定性與安全性。用戶僅需透過 ISO 隨插即用,系統便能自動啟動 Docker 環境。此外,Lightwhale 透過隔離的儲存空間處理數據持久化,不僅適用於企業邊緣運算,也適閤家庭實驗室使用,讓伺服器管理回歸高效且純粹的本質。
+ 這簡直是懶人福音!不用再為了更新套件庫或處理相依性衝突而抓狂,直接重開機就能恢復乾淨環境,維運成本瞬間降為零。
+ 不可變核心(Immutable Core)的設計非常有創意,這種「像遊戲卡帶一樣運作」的操作系統確實降低了企業部署邊緣節點的門檻。
#作業系統 #Docker #Linux #開源工具
Show Original Post
ngate (@ngate@mastodon.social)
Oh, wow, another "revolutionary" server OS that solves the problem no one had in the first place. 🚀 Just what we needed—another flavor of #Linux pretending to make #sysadmin work "fun" again. 🎉 Wake me up when it's not just #Docker slapped on an immutable ISO. 🙄
https://lightwhale.asklandd.dk/ #serverOS #innovation #critique #HackerNews #ngated
Show Original Post
labrafa (@labrafa@mastodon.world)
Tengo publicado en Youtube un tutorial que explica como instalar #Kafka Con #Docker.
Es una plataforma de streaming distribuida utilizada en aplicaciones de datos en tiempo real.
Nota: imagen generada con IA.
Show Original Post