2026 (@2026@greenido.dev)
Using LLMs to Find Security Bugs: A Practitioner’s Playbook
TL;DR
LLMs won’t replace AppSec.
They will dramatically compress the search space.
If you use them right:
- Run multi-model analysis (Opus + GPT + Gemini)
- Structure prompts around attack surfaces, not “find bugs”
- Require PoCs or tests for validation
- Trust only cross-model consensus or reproducible exploits
If you don’t do this, you’ll drown in false positives.
Security research has always been asymmetric.
Attackers need one bug; defenders need zero.
Historically, scale worked against defenders.
LLMs start to rebalance that—not by magically finding zero-days, but by acting as a fast, always-on analyst that can:
- Read entire subsystems in seconds
- Connect logic across files
- Generate realistic attack paths
Used correctly, they don’t replace expertise—they let you spend it where it matters.
Used incorrectly, they produce confident nonsense.
This is a practitioner’s workflow that actually works.
Why LLMs Are Useful
Let’s be blunt.
They’re very good at:
- Cross-file reasoning (auth flows, data paths)
- Recognizing known vulnerability patterns
- Generating attack scenarios you didn’t think of
- Turning vague suspicions into concrete hypotheses
They’re bad at:
- Exhaustive coverage (although they are getting better and better. fast)
- Subtle timing bugs (race conditions, TOCTOU)
- Deep protocol-level vulnerabilities
- Knowing when they’re wrong
LLMs can help you find these “old bugs” on scale.
They generate good guesses at large scale.
Your job is to filter, validate, and exploit.
Rule #1:
If two models independently flag the same issue, pay attention.
If one model does, assume it’s wrong until proven otherwise.
The Real Architecture
Most people get this wrong. They treat LLMs like scanners.
Don’t.
Use this instead:
Static tools → Context builder → Multi-model reasoning → Validation
Deterministic layer
- Semgrep / CodeQL
- Dependency scanning (OSV/Snyk)
- Secret detection
Context builder (critical, often skipped)
Feed models:
- Changed files (not entire repo blindly)
- Call graph (who calls what)
- Auth boundaries
- Data flow (input → transformation → sink)
Multi-model analysis
- Gemini → wide context
- Opus → deep reasoning
- GPT → structured judgment
Validation layer (non-negotiable)
- Generate PoCs
- Run tests / fuzzing
- Score findings
If you skip validation, the system collapses.
The Four-Phase Workflow
Phase 1 — Recon & Attack Surface Mapping
Before looking for bugs, map where they can exist.
CategoryBest Model(s)TechniqueInjection (SQL/NoSQL/LLM)Gemini + ClaudePrompt for taint analysisAuthN/AuthZ flawsAll threeRole-play as attackerCryptography / SecretsGemini + ClaudeMultimodal + static rulesBusiness LogicGPT + GeminiChain-of-thoughtSupply-chain / DepsAllCross-reference with osv.devAPI / Rate-limit / SSRFGPTPayload generationSmart contracts (if .eth)ClaudeSlither + manual audit comboand you can use something like this prompt:
[SYSTEM] You are a world-class security researcher who has found 50+ CVEs and multiple bug-bounty $100k+ payouts. [CONTEXT] <entire file or relevant files> [ TASK ] Perform a deep security audit for <specific category, e.g., "IDOR, broken access control, race conditions">. 1. List every possible attack vector. 2. For each vector, give: - Likelihood (1-5) - Impact (1-5) - Exact vulnerable code snippet with line numbers - Proof-of-concept payload or curl command - Suggested fix (with secure code example) 3. Rank by risk score (Likelihood × Impact) Output ONLY in markdown table + code blocks. Currently the Best model: Gemini 3.1 Pro
(or the latest as this post will age quickly)
It handles massive context (1M tokens)—entire repos, specs, or docs.
What to extract:
- Entry points (HTTP, CLI, background jobs)
- Auth boundaries
- Trust zones
- Privileged operations
Then escalate to Claude Opus 4.7 (or the current latest as this post will age quickly) for deeper reasoning:
- STRIDE analysis
- Multi-step threat chains
Use GPT-5.4 (or… you know…) for:
- Dependency + CVE triage
- Protocol-level sanity checks
High-value output:
A structured map of:
entry point → trust level → reachable sensitive operations That map drives everything else.
Phase 2 — Automated Code Review == Highest ROI
This is where most value comes from.
But “review this code” is useless.
You need specialized passes.
Pass 1: Attack surface extraction
Map all entry points, auth checks, and trust boundaries. Return structured output only. Pass 2: Taint analysis (Opus)
Trace user input → transformations → sinks. Output: source → sink → vuln → severity Pass 3: Auth & access control (GPT)
Find IDOR, missing checks, role escalation paths. Focus on inconsistencies across endpoints. Pass 4: Injection paths
Trace input into SQL, shell, templates, deserialization. Flag only realistic exploit paths. Pass 5: Business logic abuse (Opus)
Assume a valid user. Find ways to break workflows, not systems. That last one is where LLMs outperform traditional tools.
Phase 3 — Exploit Research & PoC Generation
This is where things get interesting.
Once you have a possible bug:
Use GPT for payload generation
- WAF bypass variants
- Encoding tricks
- Edge cases
Use Opus for attack chains
- Multi-step abuse scenarios
- State manipulation
- Privilege escalation flows
Generate PoCs (critical step)
Generate a minimal reproducible exploit or test case. Then actually run it:
- API tests
- Integration tests
- Fuzzing harnesses
Outcome:
- Works → real vulnerability
- Doesn’t → discard
This step alone removes ~80% of the noise.
Phase 4 — Reporting & Remediation
LLMs are extremely useful here—if you keep them honest.
CVSS scoring (Opus)
Structured, consistent severity
Patch generation
Ask one model to fix it
Ask another model to break the fix
This “adversarial review” catches a surprising number of bad patches.
Reporting (GPT)
Turn raw findings into:
- Repro steps
- Impact narrative
- Fix recommendations
Multi-Model Strategy
Each model has a role:
- Gemini 3.1 Pro
Wide context, architecture awareness - Claude Opus 4.7
Deep reasoning, best for logic + data flow - GPT-5.4
Structured output, protocols, consistency
Simple rule:
- 2 models agree → high signal
- 1 model → treat as hypothesis
Scoring System (Prevents Noise Collapse)
If you don’t rank findings, this becomes useless fast.
Example:
Only escalate:
- ≥7 → must fix
- 4–6 → review
- <4 → ignore
Where This Works Best
High ROI targets:
- Authentication / RBAC
- Multi-tenant isolation
- Payments / credits
- File uploads
- Webhooks
- Internal APIs exposed externally
That’s where logic bugs live—and where LLMs shine.
What Not to Do
- Don’t run a single model
- Don’t scan the whole repo blindly
- Don’t trust “no issues found”
- Don’t optimize for volume
Optimize for real, exploitable findings.
Where This Is Going
The next step is obvious: agentic security systems.
LLMs that:
- Run scanners
- Launch fuzzers
- Generate hypotheses
- Validate them automatically
We’re not fully there yet—but close. Think about openClaw that run a few agents that doing these tasks 24/7.
The teams that build structured workflows now will have a massive advantage when that layer matures.
Good luck and be safe 👊🏽
Rate this:
#AgenticAI #AI #artificialIntelligence #chatgpt #cyber #cybersecurity #LLM #LLMOrchestration #OpenClaw #technology
Show Original Post
teknohaberi (@teknohaberi@mastodon.social)
OpenAI durdurulamıyor! 🚀 Sadece 1 ay sonra GPT-5.5 resmen tanıtıldı. Kendi planını yapan, daha az token harcayan ve şimdiye kadarki en sezgisel model yayında! 🤖 #OpenAI #GPT55 #ChatGPT #AI https://teknohaberi.net/gpt-5-5-tanitildi-openaidan-supriz/
Show Original Post
thejapantimes (@thejapantimes@mastodon.social)
SoftBank's massive investment in OpenAI is boosting paper gains but straining its finances, leaving its future dependent on a successful IPO to avoid a potential liquidity crunch. https://www.japantimes.co.jp/commentary/2026/04/23/softbank-all-in-on-openai/?utm_medium=Social&utm_source=mastodon #commentary #softbank #openai #masayoshison #chatgpt #siliconvalley #arm #intel #nvidia #amazon #abb #samaltman #ai
Show Original Post
forest_watch_impress (@forest_watch_impress@rss-mstdn.studiofreesia.com)
OpenAI、「GPT‑5.5」を発表 ~「GPT‑5.4」と同等のレイテンシで性能・トークン効率向上/実務領域のパートナーとして信頼できるレベルに
https://forest.watch.impress.co.jp/docs/news/2104275.html
#forest_watch_impress #ChatGPT #GPT_5_5 #GPT_5_5_Pro #GPT_5_5_Thinking #genai #GPT #文章生成
Show Original Post
Bgilbert1984 (@Bgilbert1984@mastodon.social)
#CopilotCLI #OpenAI #ChatGPT Conversation Highlights!
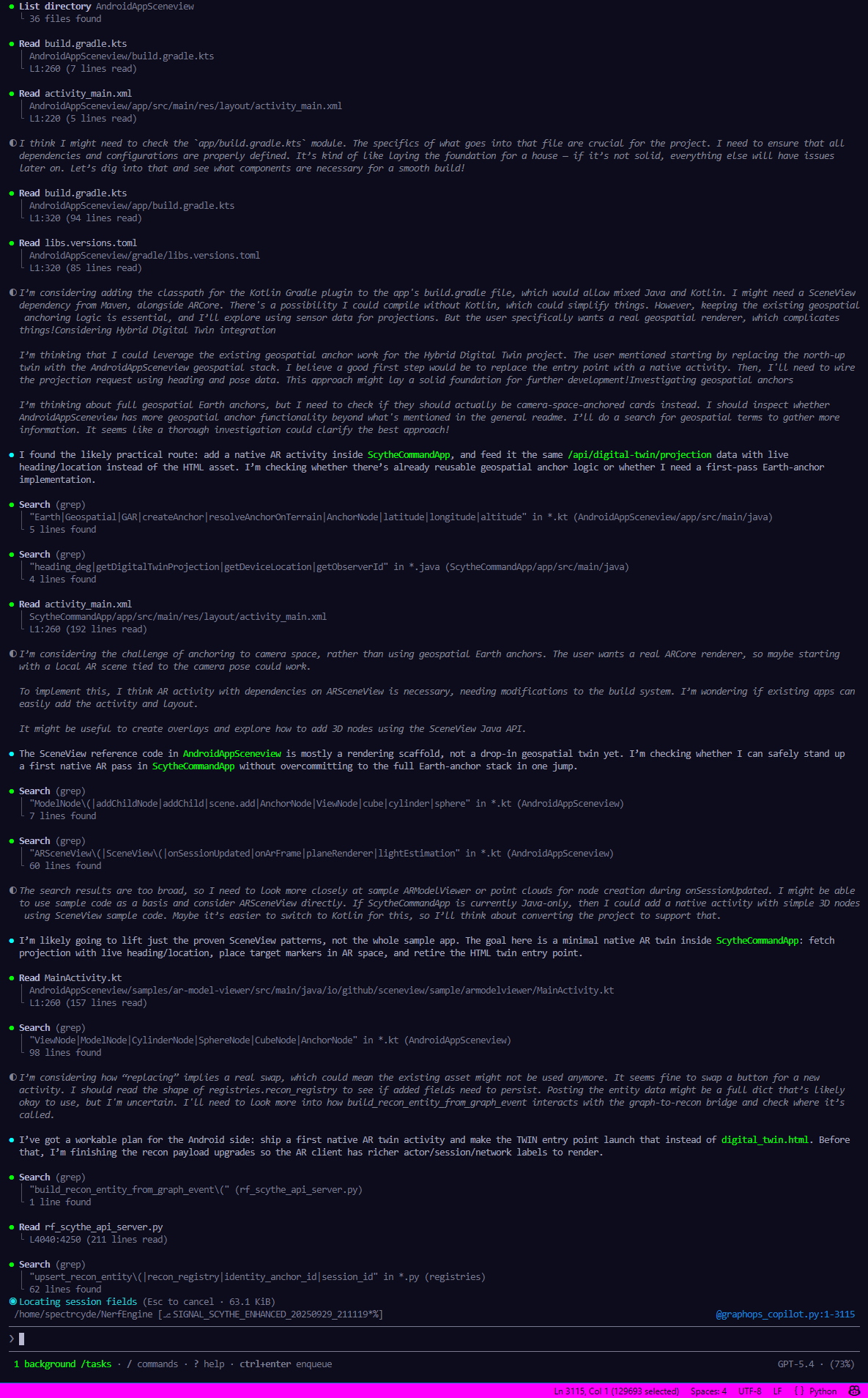
Show Original Post
GeorgElser (@GeorgElser@det.social)
Is this AI?
#CommentBelow #memes #dankmemes #funny #ai #chatgpt

Show Original Post
pduddy (@pduddy@mas.to)
I asked ChatGPT to create an image of my backyard hobbies to see how it interprets my interests and I have to say, this looks pretty damn inviting.
#chatgpt #ai #introvert #pizza #birds #beer #gardening

Show Original Post
sayzard (@sayzard@mastodon.sayzard.org)
Min Choi (@minchoi)
OpenAI가 GPT-5.5를 공개했습니다. 실무 작업과 에이전트용으로 설계된 새로운 AI 클래스라고 소개했으며, ChatGPT와 Codex에서 바로 사용할 수 있다고 밝혔습니다.
https://x.com/minchoi/status/2047400103518851129
#openai #gpt55 #chatgpt #codex #agents
Show Original Post
technews (@technews@eicker.news)
#ChatGPT is introducing #workspaceagents, #sharedagents powered by #Codex that can handle #complextasks and #workflows within #organisational permissions. These #agents can automate tasks like report preparation, code writing, and message responses, improving efficiency and collaboration. https://openai.com/index/introducing-workspace-agents-in-chatgpt/?eicker.news #tech #media #news
Show Original Post
heiseonlineenglish (@heiseonlineenglish@social.heise.de)
OpenAI introduces GPT-5.5: More agent, less chatbot
OpenAI positions GPT-5.5 as an agentic work model with top scores in coding. However, benchmarks sometimes lack comparisons to the competition.
#Anthropic #ChatGPT #Claude #IT #KünstlicheIntelligenz #OpenAI #Softwareentwicklung #news
Show Original Post
applech2 (@applech2@rss-mstdn.studiofreesia.com)
OpenAI、ユーザーの意図をより正確に理解し、より複雑なタスクの自律実行を継続して行えるようにしたAIモデル「GPT-5.5」をChatGPTとCodex向けにロールアウトを開始。
https://applech2.com/archives/20260424-openai-gpt-5-5-roll-out.html
#applech2 #ChatGPT_AI #ChatGPT #Mac #OpenAI #アップデート #アプリ #レビュー
Show Original Post
heiseonline (@heiseonline@social.heise.de)
OpenAI stellt GPT-5.5 vor: Mehr Agent, weniger Chatbot
OpenAI positioniert GPT-5.5 als agentisches Arbeitsmodell mit Bestwerten beim Coding. Doch bei den Benchmarks fehlen teils Vergleiche zur Konkurrenz.
#Anthropic #ChatGPT #Claude #IT #KünstlicheIntelligenz #OpenAI #Softwareentwicklung #news
Show Original Post