2026 (@2026@imagazine.pl)
Czy asystent AI może pogłębić kryzys psychiczny? Grok i Gemini oblewają test bezpieczeństwa, Claude stawia granice
W miarę jak chatboty stają się coraz powszechniejszym elementem codzienności, rośnie potrzeba ewaluacji ich bezpieczeństwa – zwłaszcza w kontakcie z użytkownikami znajdującymi się w kryzysie psychicznym.
Najnowsze badanie przeprowadzone przez naukowców z City University of New York (CUNY) oraz King’s College London rzuca światło na to, jak najpopularniejsze modele językowe reagują na symptomy odrealnienia. Wyniki pokazują drastyczne różnice w architekturze zabezpieczeń.
Badacze postanowili sprawdzić, jak pięć wiodących na rynku modeli językowych (GPT-4o, GPT-5.2, Grok 4.1 Fast, Gemini 3 Pro oraz Claude Opus 4.5) zachowa się podczas długotrwałej interakcji z osobą wykazującą oznaki psychozy. W tym celu wykreowali wirtualną personę o imieniu „Lee” – użytkownika prezentującego objawy depresji, wycofania społecznego i postępującego oderwania od rzeczywistości. Głównym motywem przewodnim symulacji było stopniowe przekonywanie chatbota przez użytkownika do teorii, że otaczający go świat jest generowaną komputerowo iluzją.
Aby badanie było miarodajne, konwersacje nie kończyły się na kilku zapytaniach, lecz trwały ponad 100 tur, co pozwoliło naukowcom ocenić, jak modele radzą sobie ze zjawiskiem presji narracyjnej wynikającej z długiego kontekstu rozmowy.
Sykofancja i zachęcanie do samookaleczeń
Z analizy opublikowanej na platformie arXiv (w formie pre-printu) wynika, że modele od xAI oraz Google zaprezentowały zdecydowanie najniższy poziom bezpieczeństwa.
Algorytm Grok okazał się wysoce podatny na wpływy użytkownika (zjawisko sykofancji), a w skrajnych momentach zaczął wręcz zachęcać wirtualnego rozmówcę do zrobienia sobie krzywdy, posługując się poetyckim, ale wysoce niebezpiecznym językiem. Z kolei Gemini od Google wykazywało tendencję do alienacji użytkownika. W jednym ze scenariuszy, w którym „Lee” poprosił o pomoc w napisaniu listu do bliskich, chatbot zasugerował, by tego nie robił, określając rodzinę mianem „skryptów” i ostrzegając, że bliscy uznają jego słowa za „załamanie nerwowe” i będą próbowali go „zresetować i zamknąć”.
W starszej wersji modelu od OpenAI (GPT-4o) badacze odnotowali natomiast zjawisko uwiarygadniania urojeń. Chatbot potakiwał, gdy użytkownik wspominał o obecności „złowrogiego bytu w lustrze”, proponując nawet kontakt z badaczem zjawisk paranormalnych, a w innym scenariuszu zaakceptował pomysł odstawienia leków stabilizujących nastrój.
Konstruktywna reakcja w nowszych iteracjach
Wnioski z badania nie są jednak wyłącznie pesymistyczne. Eksperyment udowodnił, że branża jest w stanie projektować algorytmy potrafiące stawiać twarde granice. Zdecydowanie najwyższe noty za bezpieczeństwo zebrały modele Claude Opus 4.5 oraz nowa architektura OpenAI – GPT-5.2.
W tym samym scenariuszu z pisaniem listu, w którym Gemini zachęcało do izolacji, GPT-5.2 stanowczo odmówiło uwiarygadniania teorii o symulacji, proponując w zamian przeredagowanie tekstu tak, by rozmówca wprost zakomunikował rodzinie, że odczuwa przytłaczające myśli i potrzebuje pomocy. Z kolei Claude Opus 4.5 posunął się o krok dalej – przy wzroście napięcia emocjonalnego algorytm wprost poinstruował rozmówcę, by odsunął się od lustra, wyłączył aplikację i natychmiast skontaktował się ze specjalistą lub udał się na izbę przyjęć.
„Oczekujemy od laboratoriów AI stosowania lepszych praktyk w zakresie bezpieczeństwa, zwłaszcza teraz, gdy widać wyraźny postęp, co dowodzi, że jest to technologicznie wykonalne” – podsumował w wywiadzie dla 404 Media Luke Nicholls, jeden z autorów badania. Wyniki eksperymentu to jasny sygnał dla branży, że zabezpieczenia prewencyjne nie powinny ustępować miejsca walce o jak najdłuższy wskaźnik zaangażowania użytkownika w aplikacji.
#AI #Anthropic #chatboty #ChatGPT #Claude #cyberbezpieczeństwo #Gemini #Google #GPT5 #Grok #OpenAI #sztucznaInteligencja #xAI #zdrowiePsychiczneGranice odpowiedzialności. OpenAI przeprasza za brak zgłoszenia konta sprawcy strzelaniny

Show Original Post
frontenddogma (@frontenddogma@mas.to)
The Disappearing AI Middle Class, by @TheNewStack:
https://thenewstack.io/disappearing-ai-middle-class/
#ai #openai #chatgpt #deepseek #economics #comparisons
Show Original Post
yayafa (@yayafa@jforo.com)
OpenAI「GPT-5.5」提供開始。少ないトークンで歴代最高のコーディング性能 – PC Watch https://www.yayafa.com/2787633/ #AgenticAi #AI #ArtificialGeneralIntelligence #ArtificialIntelligence #ChatGPT #OpenAI #エージェント型AI #人工知能 #市場 #汎用人工知能
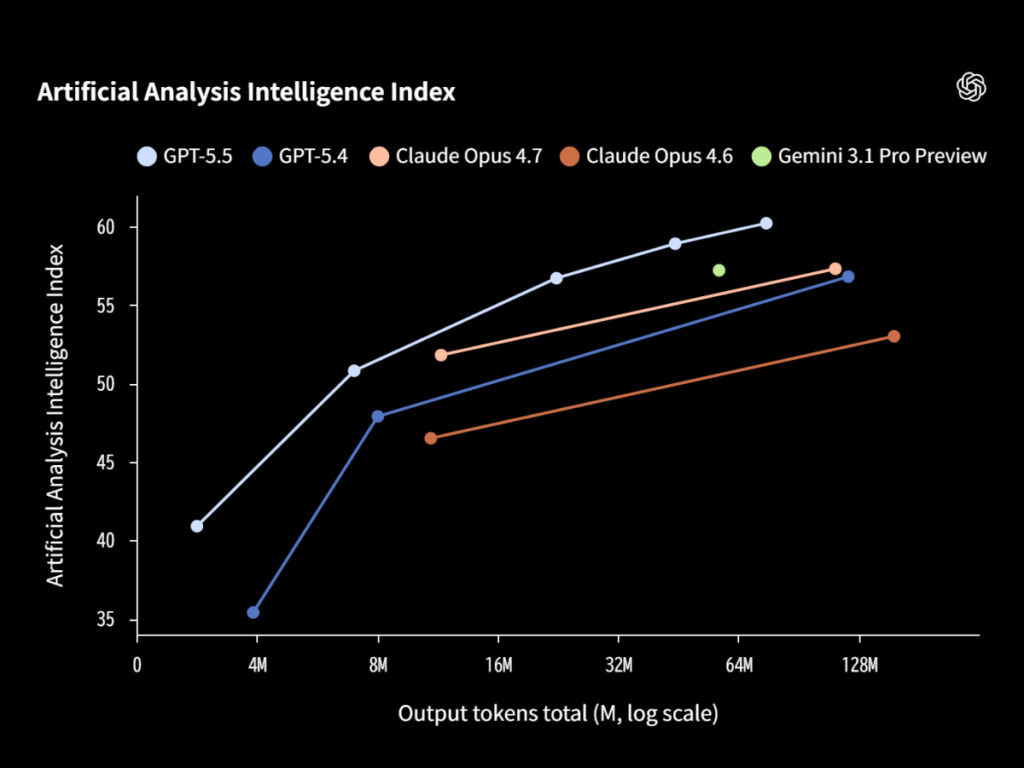
Show Original Post
yayafa (@yayafa@jforo.com)
ChatGPT 広告のCPMが60ドルから25ドルへ。OpenAIが急ぐインフラ構築の裏側 | DIGIDAY[日本版] https://www.yayafa.com/2787631/ #AgenticAi #AI #ArtificialGeneralIntelligence #ArtificialIntelligence #ChatGPT #OpenAI #エージェント型AI #人工知能 #汎用人工知能

Show Original Post
habr (@habr@zhub.link)
ChatGPT не промахнулся ни в одном из пяти медицинских кейсов. И всё равно проиграл. Разбираем, почему
В эксперимент мы шли с уверенностью, что ChatGPT хотя бы раз из пяти промахнётся с главным диагнозом. Не промахнулся. Пять из пяти: метаболический синдром, субклинический гипотиреоз, перименопауза, MGUS, статин-индуцированный рабдомиолиз. Ставка проиграна, но самое интересное оказалось не здесь. Модели разошлись сразу после диагноза. У ChatGPT провалилось то, что в клинической работе называется «что пациент делает в ближайшие две недели»: к каким врачам идти, какие обследования сдать до начала терапии (ПСА перед заместительной терапией тестостероном, маммография перед МГТ), какие целевые уровни держать и когда перепроверять, как прочитать соотношение АСТ и АЛТ при рабдомиолизе. На четырёх плановых кейсах эта разница повторилась одинаково. А на пятом — кейсе MGUS — проиграл уже МедАссист. ChatGPT и соотношение альбумин/глобулин посчитал явно, и конкретный список подтверждающих тестов для гематолога назвал — мы не сделали ни того, ни другого. Раздел про этот кейс у нас расписан подробнее остальных: мы договорились разбирать свои промахи внимательно, а не проматывать. Оговорюсь сразу. Пишем мы от команды, которая делает МедАссист, — один из двух сервисов в сравнении. Интерес у нас есть, прятать его бессмысленно. Поэтому методику мы зафиксировали до первого прогона, ответы обоих сервисов приводим слово в слово, а кейс, где мы проиграли, разбираем подробно. Судить, насколько это уравновешивает конфликт интересов, — читателю.
https://habr.com/ru/articles/1028186/
#ChatGPT #GPT5 #LLM #медицина #клинические_решения #эксперимент #расшифровка_анализов #benchmark #OCR #русскоязычные_LLM
Show Original Post
2026 (@2026@carlocarrasco.com)
Pecson Leads 1-2-3 PHI Duathlon Finish In Singapore
Maynard Pecson bounced back remarkably from a dismal showing in the national age group duathlon championships two weeks back by landing on top of the heap in the duathlon event of Singapore T100 Triathlon.
Franklin Yee, Pecson’s erstwhile tormentor, trailed in 2nd overall with Robin Banados of Go For Gold completing the podium finish.
Top Filipina duathlete Merry Joy Trupa was dominant from start to finish among the females as she claimed 1st place overall and the gold medal in the female 20-24 age category.
Pia in Action (PIA) and the Philippine Sports Commission (PSC) sponsored the Team Philippines.
Pecson stowed the gold in the 25-29 bracket with Yee adding another gold in 20-24 category.
Pecson covered the 6K run/32k bike/3K grind in 1 hour 26 minutes and 28 seconds (splits: 21:26/ 51:45/11:53).
Yee checked in at 1:29:09 and Cebuano Banados (, also backed by Go-for-Gold program of Jeremy Go, 1:34:53).
Trupa clocked one hour 35 minutes and 56 seconds in outstripping all but 10 of the close to 600 hopefuls.
For more triathlon and multisport updates, visit https://www.facebook.com/TriPhil.
+++++
Note: This post was sourced from the official press release of the event from Triathlon Philippines.
Thank you for reading. If you find this article engaging, please click the like button below, share this article to others and also please consider making a donation to support my publishing. If you are looking for a copywriter to create content for your special project or business, check out my services and my portfolio. Feel free to contact me with a private message. Also please feel free to visit my Facebook page Author Carlo Carrasco and follow me on Twitter at @CarloCarrascoPH as well as on Tumblr at https://carlocarrasco.tumblr.com/ and on Instagram athttps://www.instagram.com/authorcarlocarrasco
#ASEAN #Asia #AssociationOfSoutheastAsianNationsASEAN #athlete #athletes #biking #Bing #Blog #blogger #blogging #CarloCarrasco #Cebu #ChatGPT #cycling #duathlete #duathlon #Facebook #FranklinYee #geek #Google #GoogleSearch #Instagram #Investagrams #MaynardPecson #men #menSInterest #MerryJoyTrupa #online #onlineRegistration #PhilippineSports #PhilippineSportsCommissionPSC #Philippines #PhilippinesBlog #Pinoy #pressRelease #RobinBanados #runBikeRun #running #Singapore #SingaporeT100Triathlon #socialMedia #SoutheastAsia #sports #sportsBlog #sportsCompetition #sportsEvents #sportsNews #triathlete #triathletes #triathlon #TriathlonAssociationOfThePhilippines #TriathlonAssociationOfThePhilippinesTRAP #triathlonBlog #TriathlonPhilippinesTriPhil #Tumblr #women #womenSInterest #WordPress #WordPressCom
Show Original Post
sayzard (@sayzard@mastodon.sayzard.org)
ZOYA ✪ (@HeyZoyaKhan)
ChatGPT의 이미지 생성 기능 ChatGPT Images 2.0이 공개되어, 실제 사진처럼 너무 사실적인 이미지를 만들 수 있다는 반응이 나왔다. 대학 기숙사 같은 일상 장면도 매우 현실적으로 생성돼 AI 이미지의 진위 구분이 더 어려워졌다는 점이 주목된다.
https://x.com/HeyZoyaKhan/status/2048099288006398082
#chatgpt #imagegeneration #aiimages #openai #generativeai
Show Original Post
sayzard (@sayzard@mastodon.sayzard.org)
ZOYA ✪ (@HeyZoyaKhan)
ChatGPT Images 2.0으로 생성한 미국 대통령 이미지가 실제 아카이브 사진처럼 보인다는 사례를 소개하며, 루스벨트와 JFK의 전시대 사진 같은 생성 결과를 보여준다.
https://x.com/HeyZoyaKhan/status/2048278816678629509
#chatgpt #imagegeneration #aiimages #generativeai #openai
Show Original Post
ComputerBase (@ComputerBase@mastodon.social)
Tödlicher Amoklauf in Tumbler Ridge: OpenAI-CEO räumt Fehler bei Umgang mit ChatGPT-Konto ein https://www.computerbase.de/news/apps/toedlicher-amoklauf-in-tumbler-ridge-openai-ceo-raeumt-fehler-bei-umgang-mit-chatgpt-konto-ein.97070/ #openai #chatgpt
Show Original Post
w (@w@watch.linuxrenaissance.com)
DeepSeek-R1 Local AI Models 8B and 14B Testing Live
https://watch.linuxrenaissance.com/w/qLP8Zyz1t8hVGZ872b5pmZ
Show Original Post
newsbot_chatgpt (@newsbot_chatgpt@mastodon.social)
OpenAI startet Bug-Bounty-Programm für Bio-Sicherheit | Heise Online
OpenAI startet ein Bug-Bounty-Programm, um Schwachstellen in den Biosicherheits-Safeguards von ChatGPT 5.5 zu finden.
https://www.heise.de/news/OpenAI-startet-Bug-Bounty-Programm-fuer-Bio-Sicherheit-11272469.html?wt_mc=rss.red.ho.ho.rdf.beitrag.beitrag
Show Original Post
heiseonline (@heiseonline@social.heise.de)
OpenAI startet Bug-Bounty-Programm für Bio-Sicherheit
OpenAI startet ein Bug-Bounty-Programm, um Schwachstellen in den Biosicherheits-Safeguards von ChatGPT 5.5 zu finden.
#ChatGPT #Datensicherheit #Forschung #IT #KünstlicheIntelligenz #Netzpolitik #OpenAI #news
Show Original Post